|
| Notes:
Foil 11 of 26 In the archive signal and transcription will be automatically aligned. The precision of the alignment depends on the quality of the sound and the transcription. The alignment is based on forced speech recognition. Our system was developed using version 2.0 of Entropic's Hidden Markov Toolkit and a grapheme to phoneme converter. The input consisting of orthographic text and sampled speech data is preprocessed and then given to the HTK Viterbi decoder which does the actual alignment. The grapheme to phoneme converter partly allows to handle morphological pecularities of German which influence the pronunciation, and it can easily be adapted to any other natural language. It consists of 740 context-sensitive
rules for pronunciation and about 500 rules formulated according to a right
linear regular grammar to describe morphology. Further information will
be given within the next section.
The training material consists of six hours length with a sample rate of 16 kHz and a resolution of 16 bit per sample. The phonemes are modeled by context independent left-to-right HMMs with 3 emitting states, single mixture gaussian output probability density functions and a diagonal covariance matrix. There aren't any skip transitions per model and the model for speech pauses has the same topology. Because of the great variety of dialect forms, there is little chance to make them part of a pronunciation dictionary. Furthermore, there is no convention of how to transcribe them "correctly", and there is a need to transcribe special kinds of utterances without using the IPA transcription. Thus, a rule-based phonetization tool has to be part of the aligner in order to be flexibel enough to handle these requirements. The tool we developed transcribes words according to context-sensitive rules of pronunciation. Most of these rules are formulated according to the standard pronunciation of German and are able both to consider morphological segmentations of words or not to consider them. In general, dialect forms are not morphologically segmented but so far it has proven to work sufficiently when we enable the aligner to run on audioles of a length of 20 minutes which are completely uttered and transcribed in dialect. The results of these runs can be integrated into the database without any further correction.' R. Schmidt/ R. Neumann: Automatic Text-Speech Alignment: Aspects of Robustication in: V. Matousek, P. Mautner, J. Okélícová, P. Sojka (Eds.): Text, Speech and Dialogue, Second International Workshop, TSD '99, Proceedings, Plzen 1999. |
Notizen:
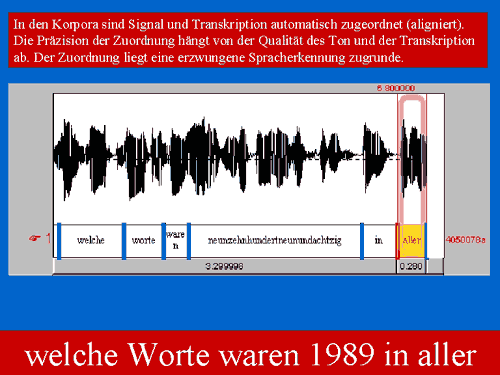
Folie 11 von 26 Es wäre wünschenswert,
die Zuordnung von Signal und Transkription automatisch zu verbessern (alignieren).
Diese Möglichkeit hängt von der Qualität des Tons und der
Transkription ab. Dem Versuch liegt erzwungene Spracherkennung zugrunde.
Es besteht aus 740 kontextsensitiven Betonungsregeln und ca. 500 rechtsbündigen Grammatikregeln, um die Morphologie zu beschreiben. HTK hängt ab von einer regulären Grammatik für den Viterbi Decoder, um den Suchbereich für mögliche Wortsequenzen zu straffen. Für die Zuordnung ist die reguläre Grammatik die lineare Verkettung von Phonemen bzw. Worten. Die einzige Variabilität ergibt sich durch die Pausen zwischen den Worten. Die Grammatik wurde so erzeugt, daß sie diese Phänomene entsprechend repräsentiert. Ein Sprachmodel ist nicht erforderlich. ins Deutsche übersetzt
aus: R. Schmidt/ R. Neumann: Automatic Text-Speech Alignment: Aspects of
Robustication in: V. Matousek, P. Mautner, J. Okélícová,
P. Sojka (Eds.): Text, Speech and Dialogue, Second International Workshop,
TSD '99, Proceedings, Plzen 1999.
|